
| 본 글은 조성수 멘토님 특강을 필기한 내용입니다. 급하게 받아적다보니 내용 검수가 제대로 되어있지 않습니다 ( 차후 다듬을 예정)
오브젝트 스토리지, 블록 스토리지와 어떤 차이점이 있는지를 알아야 한다.
오브젝트 스토리지의 가장 큰 특징 : 무한한 공간을 제공한다.
오브젝트 스토리지 톺아보기
오브젝트 : 데이터 바이너리와 메타데이터의 조합
- 데이터 : 이미지, 비디오, 문서와 같은 실제 데이터
- 메타데이터 : 데이터에 대한 부가적인 설명 ( GPS 좌표, 글쓴이, 사진기 정보 등)
오브젝트는 고유 식별자를 가진다.
어디에 저장이 될지 결정하는 지시자로 쓰인다. 다른말로는 분산 파일 시스템이라고도 한다.
오브젝트 스토리지는 폴더 구조가 없다.
- 파일 스토리지와 다르게 오브젝트 스토리지는 폴더 구조를 가지지 않는다.
HTTP REST API 를 지원한다.
- 오브젝트에 접근하는 방법으로 HTTP REST API 를 지원한다.
왜쓸까?
- 데이터 폭증/ 비정형 데이터의 증가
- 인터넷과 개인 기기의 발달로 데이터가 폭증하고, 비정형 데이터들이 증가함.
- 정형 데이터 : rdb 를 생각하면된다. 모든 데이터들이 규격화되어 저장되어있는게 예전에는 태반이었다.
- 근데 스마트폰 기기의 발달로 사람들이 생산해내는 데이터의 형태가 영상, 사진 기타 등등이 증가했다.
- 대용량 데이터 관리 요구사항 증가
- 전통적 형태의 블록 스토리지는 수천까지만 가능하고, 억이 넘어가는 순간 파일 시스템이 버벅이게 된다. 그렇기에 이렇게 대용량 대규모를 탐색할 수 있는 다른 형태가 필요해짐
- 가용성과 내구성을 매우 중요하게 생각한다. 데이터는 항상 받아져야 하고 내가 원하는때에 쓸 수 있어야 한다.
- 우리가 아는 대표적인 오브젝트 스토리지는 S3
- 오픈소스 옵젝 스토리지
- ceph
- minio
- openio
- swift
- 데이터를 다루는 관점의 차이
- 블록 스토리지는 블록 단위로 오퍼레이션이 일어나고, 흔히 말하는 ssd, hdd 정할때 포맷을 선택할 때 블록사이즈를 선택하게 되는데 이 디스크 자체를 블록으로 나눠서 저장할 건데 어느정도로 나눠서 저장할건지
- 파일 시스템에서는 무언가를 디스크에 쓸 때 블록단위로 쓰게됨
- 1kb 사이즈의 파일 저장할 때 블록(512)라면 2개에 걸쳐서 저장될 것
- 디스크에 파편화된 블록을 모아주는게 = 디스크 조각모음이 하는 일
- ssd는 디지털 신호로 접근하는 것이기 때문에 파편하되어있어도 상관없다.(동시다발적으로 cell 접근이 가능하기 때문ㅇ)
- 블록스토리지 - ssd,hdd 가 대표적
- 클라우드에서는 디스크 붙이고싶을때 블록스토리지 할당한다. (EBS)
- 하나에 연결할 수 있는거에 제한이 걸려져있음
- 오픈스택에서 kvm을 쓴다면, 24개까지 마운트 가능 ( 제한을 걸어둠)
- 보통 온프렘에서 df 했을 때에는 sda , sdb 로 네이밍이 된다. (SATA 디스크이기 때문에)
- 클라우드 인스턴스로 df 했을때에는 /dev/vda, vdb 이런식으로 (V 가 붙는 이유는 가상이기 때문에)
- 일부의 블록 단위로 수정 가능
- 오브젝트 스토리지는
- 오브젝트 단위로 업/다운로드 가능
- 일부를 수정하더라도 오브젝트 자체를 다시 올려야함 그게 바로 오브젝트 스토리지이기 때문이다.
openstack swift

openstack 이 탄생할 때부터 존재한 컴포넌트이다.
- nasa 와 rackspace 의 합작이 오픈스택인데
- rackspace 는 스토리지 기술이 강점이었다.
- rackspace 가 코드 기증했대
swift 의 주 용도는, openstack 의 이미지 데이터 저장
- swift 주 용도는 glance의 이미지 저장 백엔드 스토리지이다.
- 독립형으로 구동할 수 있는 특징 때문에 object storage 서비스 단독으로 운영이 가능하다.
- 유일하게 독립적으로 사용가능하다.
- 그 어떤 컴포넌트하고 유기적으로 동작하지 않는다.
- 키스톤을 안쓸수도 있고, 쓸수도있고
- 대표적으로 트위치에서도 이걸 썼다고 함
- 지금은 swiftstack이 엔비디아에 인수되면서, 주요 메인테이너가 nvidia 로 이직함.
- ai 학습데이터는 오브젝트 스토리지에 저장하기 때문에 눈여겨본다고 함
swift 데이터 구조
Account
- swift 의 최상위 개념으로 swift 를 이용하기 위한 계정
- 테넌트
- 어카운트 안에 컨테이너가 있음
container (s3 bucket)
- 오브젝트 목록을 가진 데이터 베이스이다.
- 컨테이너 이름은 하나의 어카운트 내에서는 중복될 수 없지만, 스위프트 전체적으로는 가능하다.
object
- 오브젝트 그 자체
- 단일 오브젝트는 최대 5gb 이상이 될 수 없다. 일정 단위로 클라이언트 단에서 잘라서 올려야 한다.
- 왜 5gb 인가?(왜 제한했을까?)
- 운영적 측면에서 특정 파일이 너무 커버리면 불균형이 발생하기 때문에 이를 방지하기 위해 최대사이즈를 제한해둔 것
- 5gb 의 규모가 커지면 (여러개로 ) 사용량이 비슷해진다.
- 만약 5gb 보다 커지면 멀티파트로
데이터 표현
/account/container/object
ex ) /auth_testuser/test_container/a/b/c/test_object.txt
아마존은 버킷명(도메인에 들어가서 중복이 안된다고 함)
아키텍처
- proxy-server : 오브젝트를 처음 받았을 때 수행하느 기본적 동작을 다 수행함
- account/container/object 서버로 전달 요청
- account-server : account 정보를 저장하는 db 요청 - sqlite3 (안드에서 쓰이는 경량화된 디비 이걸로 관리한다고 )
- container-server : container 정보를 저장하는 db 서버
- object-server : object 물리적인 디스크 저장
sqlite 는 복제를 지원하지 않아서 swift 가 복제 구성
값싸고 저렴한 서버로 용량을 크게해서 전체적인 운영 cost 를 낮추는게 목표라서 스펙이 엄청 고가의 장비를 쓰지는 않고 x86 에 16TB 하드디스크를 붙임
성능이 중요하기보다 규모만 크면되기 때문이다.
내부 통신
- proxy server 는 http기반 rest api 제공함
- proxy ↔ account/container/object 사이의 통신도 모두 http rest api 를 통해 이루어짐
- 하나의 요청이 여러 노드를 거쳐 처리되기 때문에 모든 요청에는 transaction id 를 생성해서 로그에 기록한다.
- 내가 보낸 요청이 어느 서버에 가서 로그를 남기는지를 추적해야하기 때문에 트랜잭션 아이디로 로그를 분석함
swift 네트워크 구성
client
service
proxy-server
data
account-server / container-server / object-server
replication
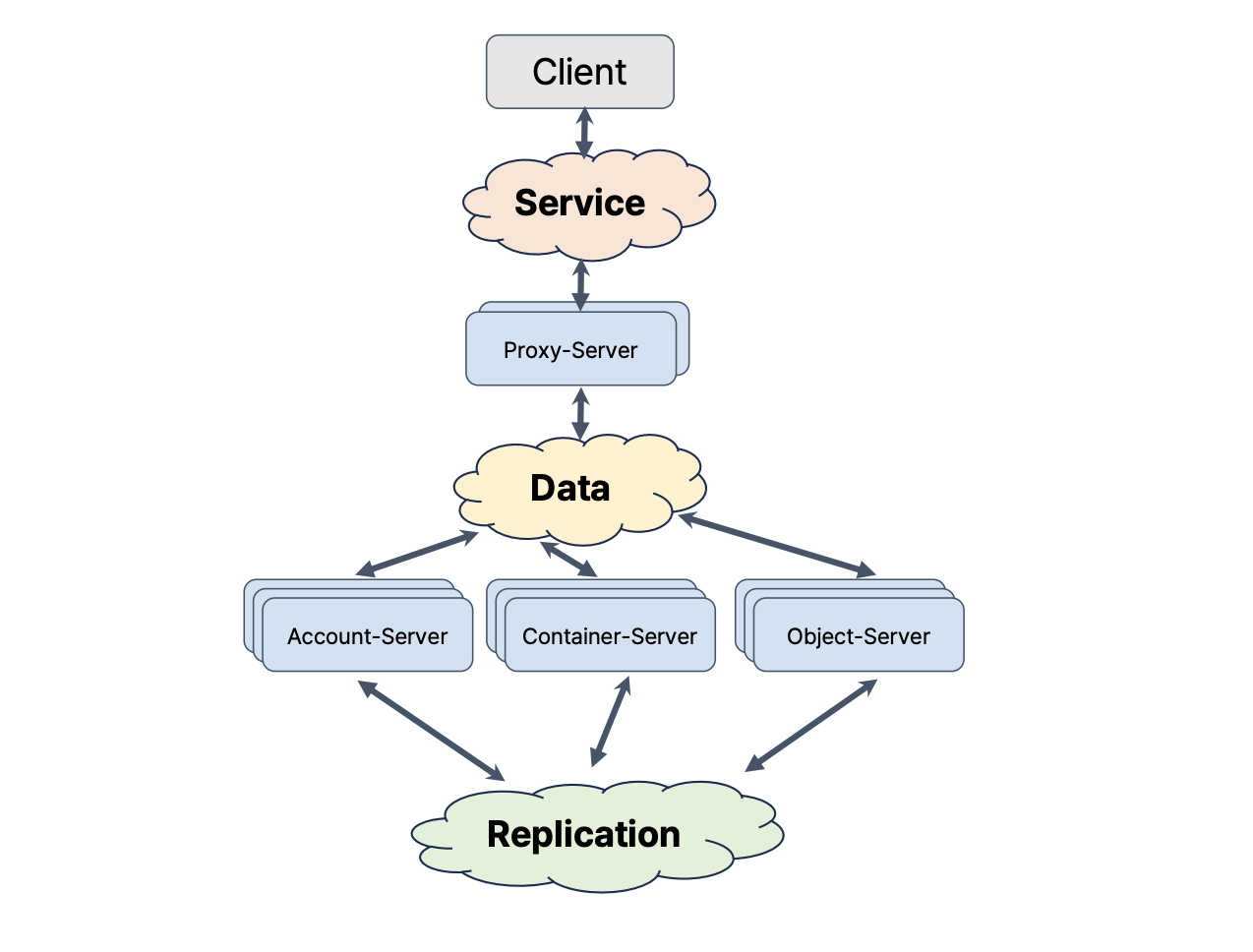
프록시 서버까지는 공개망,
아랫부분은 사설망으로 구성되어있다. ( 외부접근 x)
내 계정에 대한 인증정보를 담아야 하기 때문에, 인증이 안되어있으면 프록시서버는 402 오류 발생
내부 프록시 망은 인증정보 필요없어서 신뢰할 수 있는 네트워크여야만한다.
replication nw 는 분산스토리지가 3 copy 를 하니 언제든 노드의 장애가 발생할 수 있는데, 이를 복구하기 위한 것이 복제 트래픽임.
근데 이게 서비스 트래픽과 겹치면안되기 때문에
서비스 트래픽과 복제 트래픽을 분리한다.
복제 트래픽이 많더라도 서비스가 원활히 굴러가도록 분리해둔다.
ex )업로드 트래픽이라면,
100MBps 속도로 올라오고 온다면, 이때 3copy 로 저장해야한다.
프록시 노드는 들어오는게 100MBps 라면 나가는건 300MBps 가 된다.
그래서 서비스 단에서는 나가는 크기를 더 크게잡아야 함. 안그러면 트래픽이 눌린다.
서비스네트워크를 아무리 빵빵하게 해놔도, 디스크의 성능 한계가 걸리기 때문에, 일반적인 sas , sata 쓰게 되면 다운 스피드가 1.3 MBPS 가 되기 때문에 ..(?)
swift 의 모든 데이터는 3개의 복제에 저장
오브젝트 업로드 → 3개의 노드에 동시저장 → 한대가 죽었을 경우
- 업로드 실패하면 안됨!
- 고가용성 유지가 되어야 한다.
- 노드 c에 저장하지 못했더라도, 요청은 성공시키고 c r가 다시 살아나는 시점에 a,b 가 c 에 다시 복제 시킴
반드시 모든 노드에 동시에 저장할필요가 없다.
일정 수 이상의 노드에만 저자앻ㅆ따면 성공한 것으로 간주
quorum : ( 복제본 수 / 2 ) +1 == 정족수
복제본은 무조건 홀수, 짝수는 절대 과반을 만들수 없게 때문에
3copy 라면 2copy 만 저장이 되어도 okay 인거임
정족수를 만족하면 시스템은 정상동작한다.
1대에 저장하지 못했다고 하더라도, 정족수를 만족하기 전에 전체 시스템은 정상적으로 동작한다.
단, 최신 데이터가 복제되기 전까지 노드 c 로 요청이 오면 과거 데이터를 줄 수 밖에없다.
하지만 언젠간 데이터는 복제되기 때문에 okay 이다.
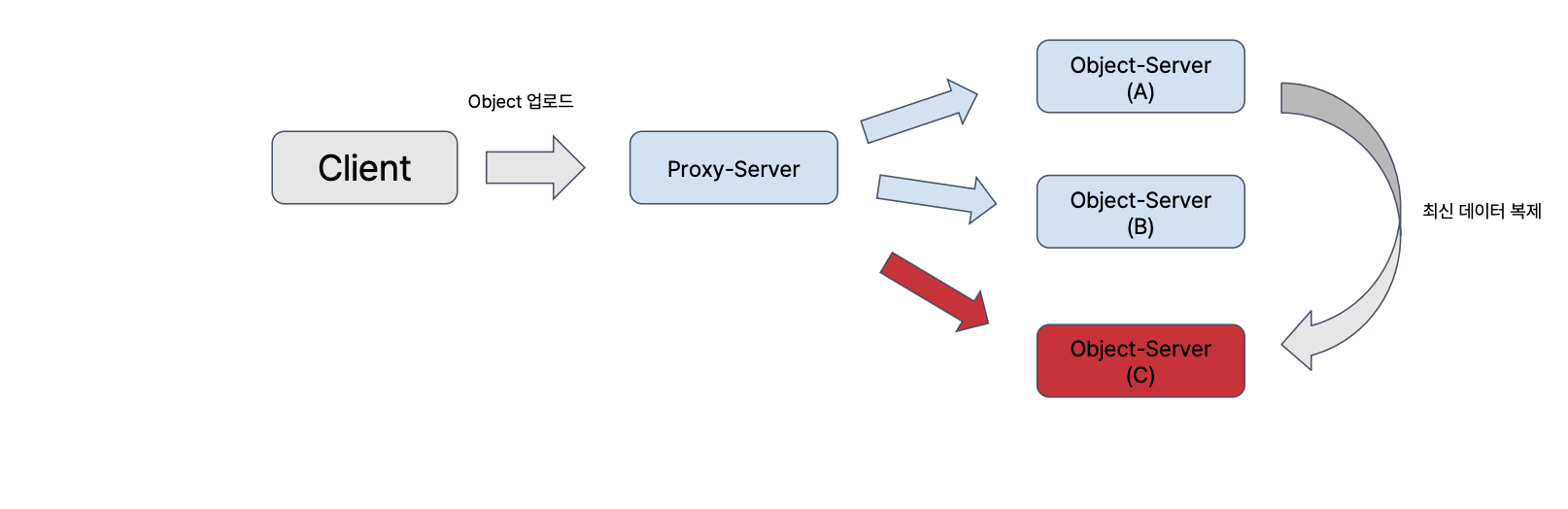
언젠간
많은 오브젝트 스토리지 서비스들에서는 데이터의 가용성을 보장하지만, 최신성을 보장한단느 이야기는 거의안한다.
이걸 깬놈 : 아마존 s3 strong consistency 를 발표했다,,.
이게 왜 불가능 하느냐!
분산시스템에서는 cap 에서 ap 만을 취하는 전략을 가져감
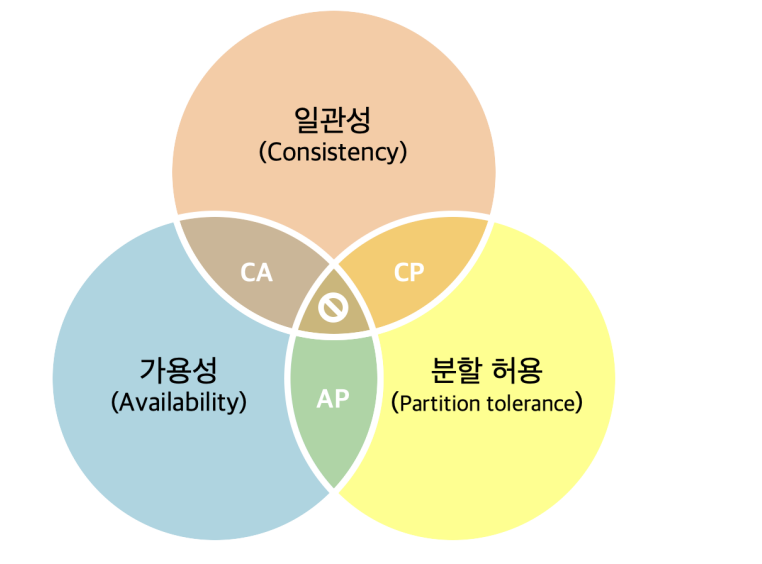
일관성(데이터는 항상 동일),가용성(서비스의 연속성), 분할허용(장애 발생해도 정상적으로 ㄱㄱ)
스위프트는 분할허용과 가용성을 보장하는 대신 일관성을 포기했기 때문에 언젠가는 보장한다고해서
eventually consistency 라고 부른다.
대부분 normal 한 상황에서는 3copy 가 저장된다.
만약 2대가 죽으면, 정족수를 만족시키지 못하므로 업로드 실패.
과연 2대 고장났다고 서비스가 불가능할지?
어떻게 일관성을 포기하는대신에 고가용성을 가져가는지
openstack swift 고가용성 전략
어떻게 유지할 수 있는지
일관성을 포기하는대신에 고가용성을 가져가는지
어디에 데이터를 저장할 것이낙?
물리적으로 ) 어느 서버/ 어느 디스크/ 어느 경로
저장할 곳이 고장나면, 어디로 가야하는가?
consistent hash ring
이걸 기반으로 독자적인 링을만들어서 데이터가 저장되는 위치 결정함
hash ring 이론
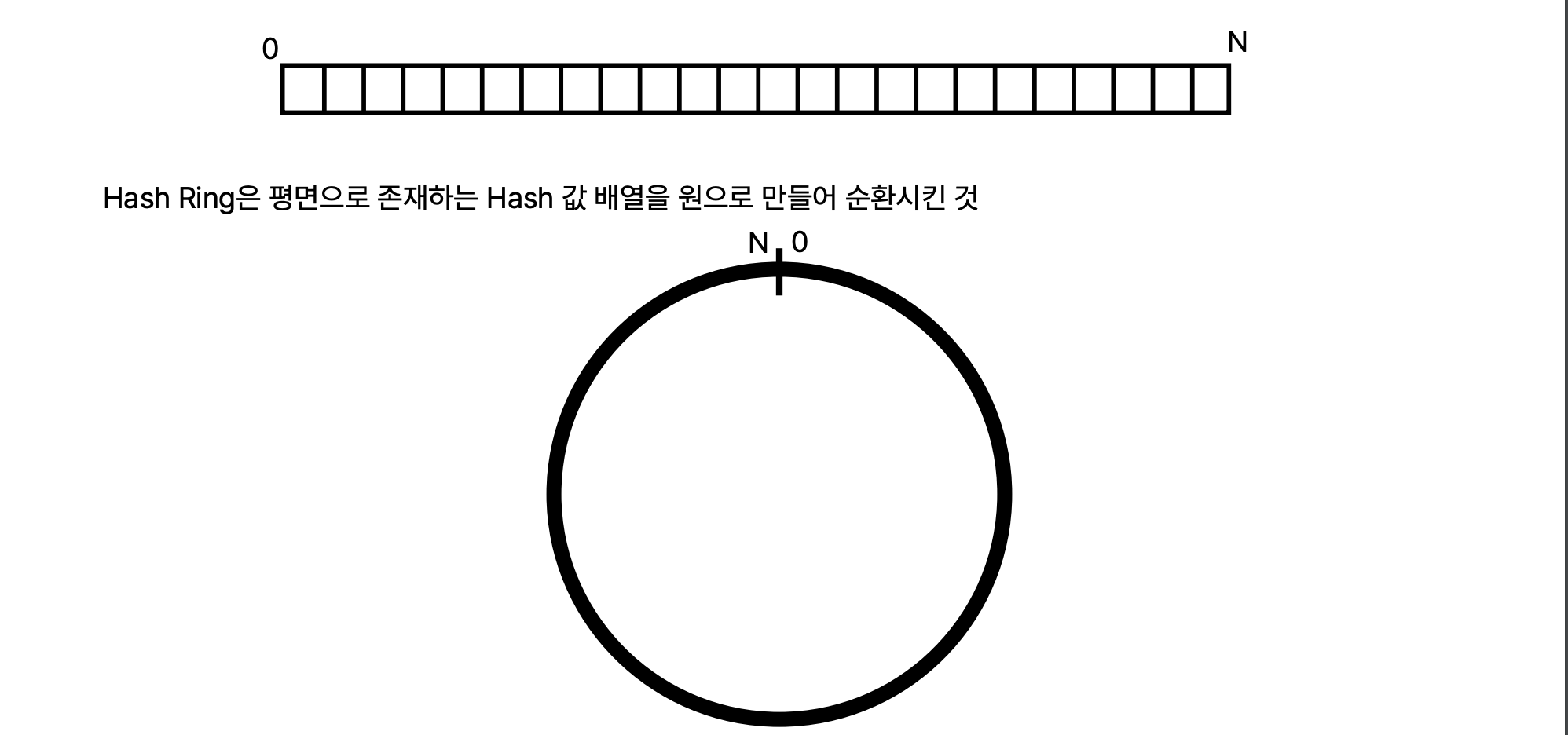
hash 라는건 0부터 끝자리가 있는 1차원 배열 숫자이고,
ring 은 원형이다.
hash 의 끝과 끝을 묶어서 원형으로 만든게 Hash ring
데이터를 저장할 서버의 지시자 ( ip)를 해시한 값을 링에 배치함
키가 저장될 서버는 원을 시게방향으로 선회하면서 만나는 첫번째 서버이다.
중간에 서버가 추가되면, 데이터의 저장위치가 변경된다. (재배치 작업)
기본 개념에는 여러 한계가 존재한다.
해시는 랜덤이기 때문에 데이터의 해시키가 특정 노드에 몰릴 수 있다.
해시는 O(1)이다.
파티션의 크기를 노드별로 균등하게 배치할 수 업삳. 노들르 해시 위치에 따라 노드별로 담당해야하는 영역이 다르다.
노드를 중복해서 배치하는 가상 노드 기법등 다양한 기법들이 추가된다.
기본개념에서 swift 만의 독창적인 개념을 추가한 ring 을 만들었다.
오픈스택에서는 링을 정말로 링이라고 부른다.
openstack swift 에서 ring 이란
오픈스택에서 링이란 일종의 파일이다
각각 만들어짐
오브젝트/어카운트/컨테이너가 어느노드(서버)에 저장되어야 하는지 기준이 되는파일
모든 노드에 링파일이 저장되어야한다.
- 모두 동일한 내용이어야만함
Ring 의 요소
- partion power : 파티션 개수를 결정짓는 요소
- 2^N개의 파티션을 만드는데 partion power 는 N을 의미한다.
- 파티션 : 링을 몇개의 구간으로 쪼갤 것인가
- Number of Replication
- Device List
- Device Lookup Table
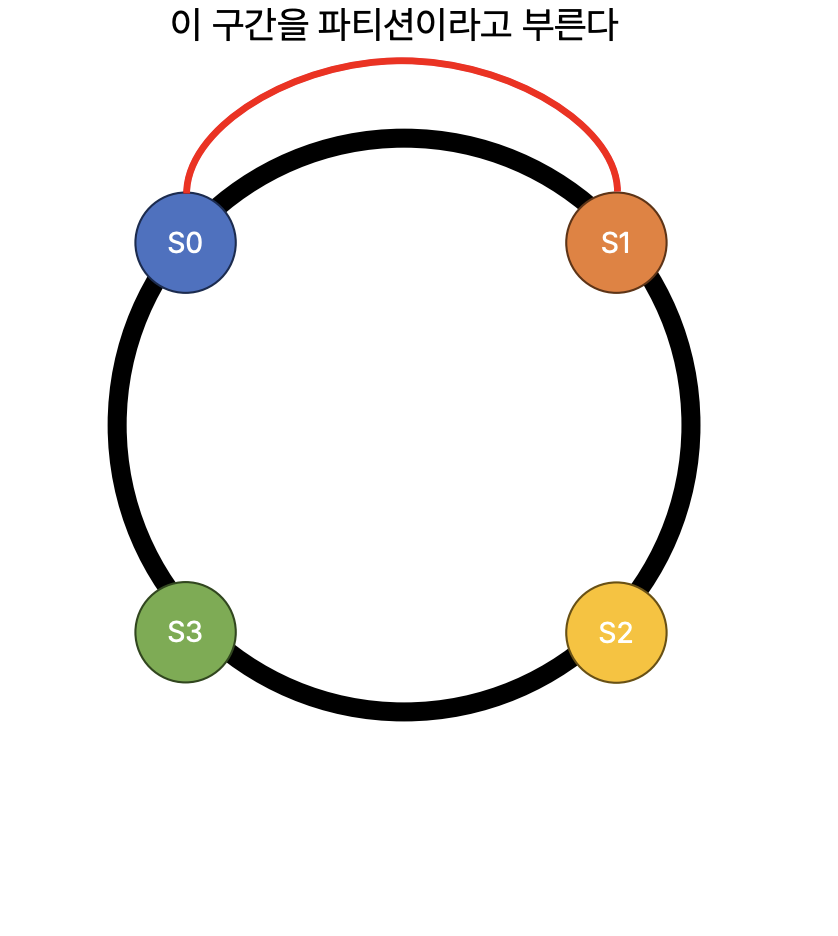
device list
- swift 가 사용할 디스크에 접속할 수 있는 정보를 1차원으로 나열한 배열
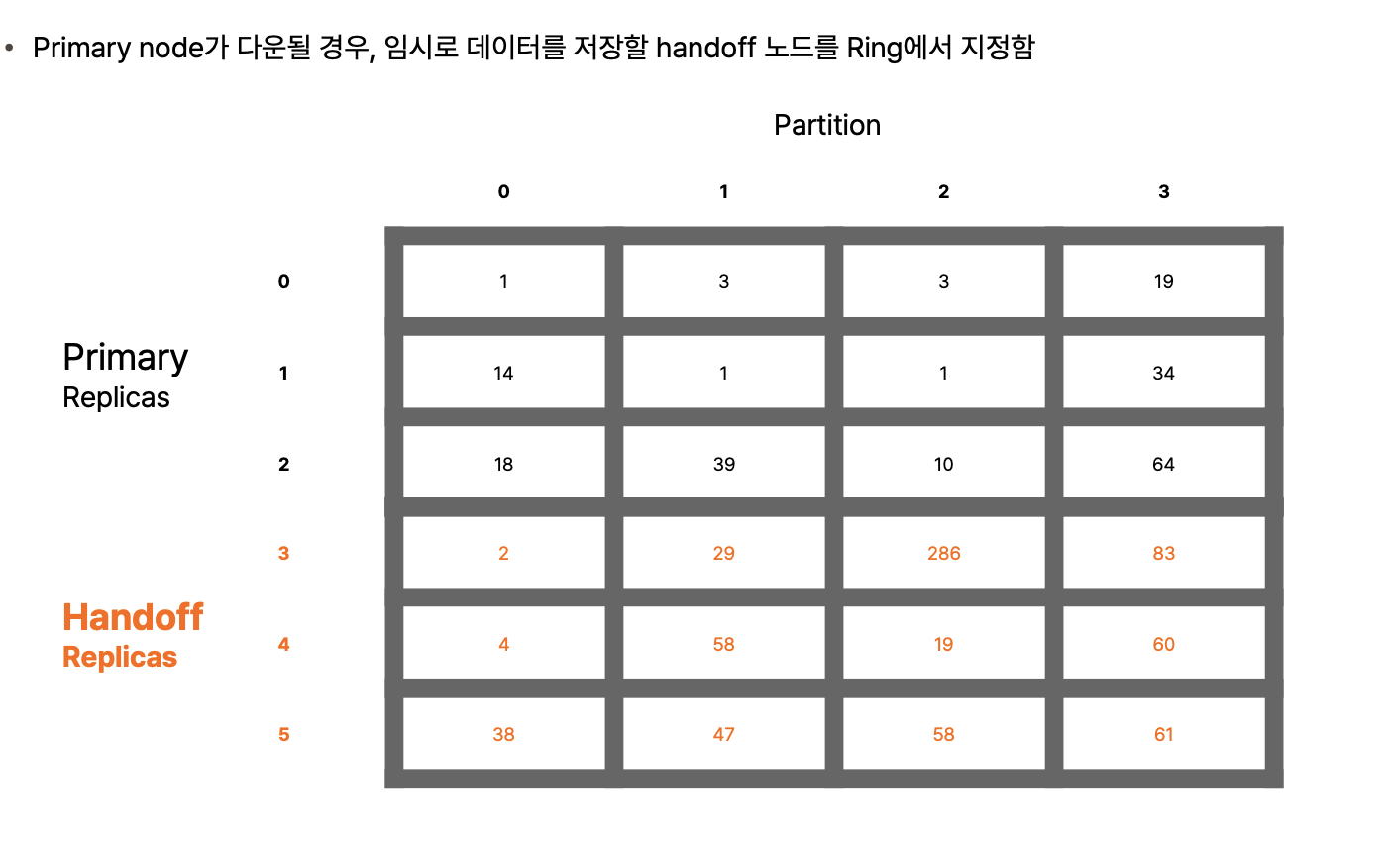
device lookup table
- 파티션마다 복제본이 어느 디스크에 저장되어야 하는지 지정하는 테이블
- 행: 복제본의 개수
- 디스크의 인덱스가 파티션의 값이됨
주 노드 다운을 대비한 handoff 노드
- 메인으로 저장해야 할 3개를 primary replicas
- 여분 handoff replicas
- 그래서 총 8개의 디바이스
- 어느 파티션에서는 주 레플리카, 어느 파티션에서는 예비로 핸드오프를 받아준다.
- 예비장비라는 개념은 없고 서로가 서로의 백업이 되어준다.
- 열에는 중복된 숫자가 없다.
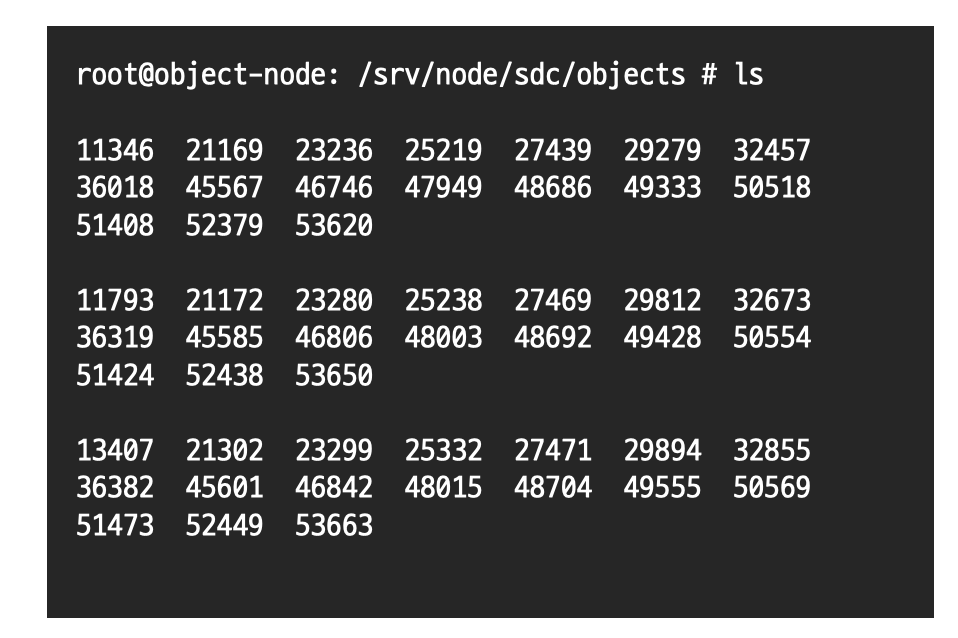
단일 디스크 관점에서 본 데이터 저장 구조
- swift 에서 디스크를 마운트하는 기본 경로 /srv/nodes
- ex) sdb/ sdc /sdd 디스크를 swift 에서 사용한다고 했을 때
/dev/sdb -> /srv/nodes/sdb
/dev/sdc -> /srv/nodes/sdc
/dev/sdd -> /srv/nodes/sdd
이런식으로 마운트 쭉 시킴
단일 디스크관점에서는 /srv/nodes/sdb/objects 하위에 그 안에 파티션 번호로 폴더가 만들어진다.
파티션 폴더 안에 데이터가 저장된다.
데이터가 들어왔을 때 만들어짐
파티션단위로 데이터를 뭉치는 것이다.
아 ~어렵다알고리즘 시작되자마자 정신잃음
저장할 위치 결정하기
- proxy 서버가 각 요소의 이름을 md5 해시한다.
- account - md5(/AUTH_user1/container1)
- md5 값을 Ring 을 생성할 때 지정한 partition 값으로 mod 연산을 한다.
- 왜 md5냐면 가장 빠른 해싱 알고리즘이기 때문이다.
- ex ) 2205~~~~ % 2048 = 140
- 140 이라는 값은 device lookup table 에서의 파티션 열의 번호이다
- 해당 열의 replica 로 지정된 device 번홀 잉용해서 데이터위치 결정
- 해시 값이 충돌할수도있음 ( 퍼브릭 클라우드에서는 특히) → 다만 감지가 어려움
- 다른 고객의 데이터를 덮어씌울수도있기 때문에 문제가 발생한다.
object server 증설 방법
- device list 에는 가중치 정보도 있다.
- 이 디스크가 전체 풀에서 차지하는 가중치
- 얼마나 많이 노출이 되느냐
- 운영에선 중요한 값이 된다. 매번 상황에 따라 달라지고, 가중치가 클수록 더많은 파티션 할당됨
- 새로운 노드가 들어오면 device list 에 새로운 디스크가 추가된다. 새롭게 추가된 디스크는 디바이스 룩업테이블에 배치되어야 한다.
- 디바이스 룩업 테이블의 내용이 달라진다 == 파티션에 디스크가 재배치된다 == 리밸런스
- 데이터가 옮겨지기도 전에 새로운 데이터가 저장되어 버리면 안되기 때문에 특정 기준치 이상으로 가게된다면 리밸런스를 한번에 안시킴
- 3copy 중에서 무조건 디스크 하나씩만 옮겨가게 해야 안정적으로 데이터를 업/다운이 가능하기 때문이다.
재배치 작업
- 내꺼에 있는지 아닌건지를 먼저 검사한다.
- 밀어주는 방식으로 복제를 떠준다. )( 이거 내거아니야 너 써 리눅스 Rsink 로 폴더 잡고 딱 때려버림)
- 노드 다운 되었다가 다시 올라온 경우
- 구 노드는 과거 데이터이기 때문에 rsync 로 보내줘야함
- 그래서 스위프트는 파티션 단위로 해싱을 떠놓음 (이게 구 데이터인지 알 수 없기 때문에)
- 그래ㅓㅅ 나랑 비교했을 때 해시값이 일치하면 데이터를 안보내고, 일치하지 않으면 rsync 한테 새 데이터를 요청
- rsync ignore existing - 더 최신인 데이털ㄹ 보내줘 이미있는거 빼고
- 서비스 특성에 맞게 변경, 조정함
- ceph 같은 경우
- 트래픽에 맞게 리플리케이션의 비율을 줄이고데이터 트래픽을 늘리고
- 사용자 량이 적을 때에는 리플리케이션 늘리고..
데이터 재배치 작업은 서비스에 영향을 준다.
한 번에 너무 많은 파티션이 재배치되지 않도록, 새로 투입하는 디스크의 weight을 조절하며 Ring에 투입해야 한다 • Weight값을 100 -> 300 -> 1000 -> 목표값 까지 순차적으로 늘리면서 투입한다
이르케 하면 노드 투입이 완료됨
저장될 공간을 다양하게 만들자 : Storage Policy
- 고성능의 디스크 써줘.→ nvme
- 데이터 저렴하게 할래요 → 2copy
- 비즈니스 요구사항에 따라서 디스크 저장 방식을 다르게 하는걸 스토리지 폴리시라고 한다.
Object Storage Swift의 Account와 Container
Account / Container 는 데이터 베이스이다
- OpenStack Swift는 데이터 베이스로 SQLite를 사용한다
- SQLite 파일도 내부적으로는 하나의 오브젝트처럼 취급되어, 3개의 복제본을 만든다
- 3개의 복제본 DB의 내용이 항상 일치하도록 정합성을 실시간으로 맞춘다

컨테이너 서버가 3대중에 한대가 죽었을 경우
하나에만 라이트가 안들어간 상태에서
한대가 올라왔을 때 DB 에 데이터를 받아와야 한다.
받는 와중에 업데이트를 받게되면 로우가 깨지기 때문에
스위프트에서는 몇번째 로우 번호까지..어쩌고
row 번호를 비교해가며 갱신/업뎃/
삭제 - 기존에 있던 row 를 지우는게 아니라 새로운 row 를 쌓음
row 개수 격차가 전체 50% 이상이 되면 그냥 더 최신거로 업뎃
초당 10만건을 받는데 그중에 3분의 1을 한 컨테이너가 담당하고있다.
초당 3만컨이 한컨테이너 한 디비에 보내니 sqllite 가 버티지를 못한다.
오브젝트 목록이 3copy db끼리 안맞는 상황이 발생함
이걸 어떻게 해결?
대규모 요청은 정확성이 깨지는 상황발생함
sqllite 에서도 한 컨테이너에 천만개 이상을 보내지마라고 함.
디비에 쓰는것 자체가 오래걸리기 때문에 데이터가 안맞게 됨
아마존 s3는 하나의 오브젝트 개수제약이 여튼 별로 없음
Object Storage Swift 의 안정성을 담당하는 데몬
미세한 오류를 잡아주는 , 받쳐주는 데몬
Swift에는 고가용성과 안정성을 유지하기 위한 여러 데몬이 있다 • Replicator • Updater • Auditor • Reaper • Expirer
오브젝트 스토리지는 ceph 도 되고, 상용 스토리지를 사용해도 된다.
후기)
너무 두서없지만
내용 자체는 정말 흥미로웠습니다.
단순히 오브젝트 스토리지 - 객체스토리지 - s3 다 이정도로만 알고있던 햇병아리에게
임금님 밥상을 보여준느낌...
멘토님의 약 10년간의 노고를 한두시간만으로는 온전히 받아들일 수 없었다는 사실이 슬펐습니다.
실무에서 고민하고 이해해야하는 부분이 이것보다 훨씬 더 딥다이브 해야한다는 사실이 저를 참 ..
한계를 느끼게 만들어준 시간이었습니다....
눈물납니다...
'☁️2024,2025☁️ > Openstack' 카테고리의 다른 글
| Openstack 설치 및 모니터링 환경 구성하기 #1 (0) | 2024.10.18 |
|---|---|
| Openstack 기여하기 #4 (0) | 2024.10.04 |
| Openstack 기여하기 #3 (0) | 2024.09.12 |
| Openstack 기여 하기 #2 (2) | 2024.09.02 |
| Openstack 기여 하기 #1 (1) | 2024.08.26 |