
클라우드 '만' 편식하다보니 모니터링을 제대로 해보지 못했었는데,
모니터링에 대해 공부하고, 설계할 기회가 생겨서 정리해둔 글을 덧붙이며 작성해봅니다.
꽤나 많은 내용을 단시간내에 공부했었기 때문에 장편(시리즈..)이 될듯 합니다.
‼️ 제 글이 정답은 아닙니다. 모니터링 초보의 설계..이니 참고정도만 부탁드려요 ‼️
컴퓨터 화면이 다크모드일 경우 글자가 안보일 수 있습니다. ㅜㅜ
가장 먼저, 인프라 모니터링 vs 어플리케이션 모니터링부터 간단하게 알아보았습니다.
어떤 차이점이 있는지 알고싶었습니다.
인프라 모니터링 vs 어플리케이션 모니터링 ?
인프라 모니터링
- 정의: 인프라 모니터링은 서버, 네트워크 장비, 데이터베이스 등 IT 인프라의 성능과 가용성을 모니터링하는 것입니다.
- 주요 기능: 하드웨어 성능(예: CPU 사용량, 메모리 사용량, 디스크 I/O 등) 모니터링 네트워크 트래픽 및 대역폭 사용량 분석 시스템 가용성 및 다운타임을 추적합니다.
- 목적: 인프라의 안정성을 보장하고, 장애를 사전에 예방하기 위해 시스템의 상태를 지속적으로 감시합니다.
어플리케이션 모니터링
- 정의: 어플리케이션 모니터링은 소프트웨어 애플리케이션의 성능과 사용자 경험을 모니터링하는 것입니다.
- 주요 기능: 애플리케이션의 응답 시간, 처리량, 오류율 등을 추적 사용자 행동 분석 및 사용자 경험 개선 API 호출 및 데이터베이스 쿼리 성능 모니터링입니다.
- 목적: 애플리케이션의 성능을 최적화하고, 사용자에게 원활한 경험을 제공하기 위해 애플리케이션의 상태를 감시합니다.
kubernetes 환경에서 특정 서비스가 동작하고 있다면
인프라 모니터링의 경우,
Kubernetes 클러스터의 노드, 컨테이너, 네트워크, 스토리지와 같은 인프라 구성 요소의 상태와 성능을 모니터링합니다.
또한, CPU 사용량, 메모리 사용량, 디스크 I/O, 네트워크 트래픽 등의 메트릭을 수집하여 클러스터의 건강 상태를 파악합니다.
클러스터의 리소스 할당 및 사용 현황을 모니터링하여 최적화할 수 있습니다.
애플리케이션 모니터링의 경우,
Kubernetes에서 실행되는 애플리케이션의 성능과 상태를 모니터링합니다. 애플리케이션의 응답 시간, 오류율, 트랜잭션 수 등의 메트릭을 수집하여 애플리케이션의 성능을 분석합니다. 로그 수집 및 분석을 통해 애플리케이션의 문제를 진단하고 해결할 수 있습니다.
결론적으로, 효과적인 모니터링을 위해서는 두 가지 측면을 모두 고려해야 하며, 이를 통해 클러스터의 전반적인 성능과 안정성을 유지할 수 있습니다.
저는, 평소 인프라 관련된 것들을 공부했었기 때문에 인프라 모니터링에 조금 더 중점을 맞춰 설계해보고자 했습니다.
인프라 모니터링에 관한것들을 찾아보다가, 좋은 글들을 발견했습니다.
아래 글 부터는 다른 글들을 발췌 해오며 공부했던 기록입니다.
인프라 모니터링이란? (ITM)
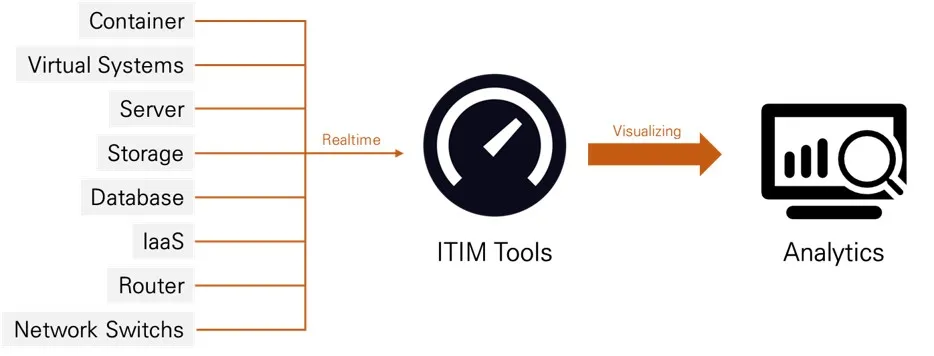
글로벌 IT분야 연구자문 기업인 “가트너(Gartner)”에서는 ITIM, 즉 EMS를 데이터센터, Edge, IaaS(Infrastructure as a Service), PaaS(Platform as a Service) 등에 존재하는 IT인프라 구성요소의 상태와 리소스 사용률을 수집하는 도구로 정의하며, 컨테이너, 가상화시스템, 서버, 스토리지, 데이터베이스, 라우터, 네트워크 스위치 등에 대한 실시간 모니터링이 가능해야 한다고 서술합니다.
클라우드 환경으로의 전환
클라우드(Cloud)란, 언제 어디서나 필요한 컴퓨팅 자원을 필요한 시간만큼 인터넷을 통해 활용할 수 있는 컴퓨팅 방식으로, 최근 기업들은 각자의 목적과 상황에 맞게 AWS, MS Azure와 같은 Public Cloud 및 OpenStack, Nutanix 등을 활용한 Private Cloud 등의 환경으로 기업의 전산설비들을 마이그레이션 하고 있습니다. 클라우드로의 전환과 기술의 발전에 따라, EMS의 IT 인프라 모니터링은 더 이상 *On-Premise 환경에서의 접근이 아닌, Cloud 환경, 특히 MSA(Micro Service Architecture)를 기반으로 하는 클라우드 네이티브(Cloud Native) 관점에서의 IT 운영 관리라는 새로운 접근이 필요하게 됐습니다. (*On-Premise : 기업이 서버를 클라우드 환경이 아닌 자체 설비로 보유하고 운영하는 형태)
클라우드 네이티브란, 클라우드 기반 구성요소를 클라우드 환경에 최적화된 방식으로 조립하기 위한 아키텍처로서, 마이크로서비스 기반의 개발환경, 그리고 컨테이너 중심의 애플리케이션 구동환경 위주의 클라우드를 의미합니다. 클라우드 네이티브는 IT비즈니스의 신속성을 위해 도커(Docker)와 같은 컨테이너를 기반으로 애플리케이션이 운영되므로, EMS는 컨테이너의 성능, 로그, 프로세스 및 파일시스템 등 세부적인 관찰과 이상징후를 판단할 수 있는 기능들이 요구되고 있습니다.
다양한 IT 요소들을 통합적으로 모니터링하는 것 뿐만 아니라, 상호 연관관계를 표현하고 추적할 수 있는 기능들이 지속적으로 요구되고 있습니다. 모니터링의 트렌드는 서버, 네트워크 등의 독립적인 개체에 대한 모니터링 아닌 IT 서비스를 중심으로 기반 요소들을 모두 통합적으로 모니터링하고, 각 상호간의 의존성과 영향도를 파악해 RCA(Root Cause Analysis) 분석을 가능하게 하고 이를 통해 IT 서비스의 연속성을 보장할 수 있는 통찰력을 확보하게끔 하는 방향으로 흘러가고 있습니다.
모니터링이 중요한 이유
정기적인 건강 검진이 사람에게 중요한 것과 마찬가지로 클라우드 모니터링은 조직에 매우 중요합니다. 건강 검진 중에 이상이 발견되면 담당 의사가 문제를 해결합니다. 클라우드 모니터링 중에 문제가 발견되면 IT 관리자가 문제를 해결하거나 해당 문제로 인해 애플리케이션 성능, 가용성 또는 보안이 저하되지 않는지 확인하는 해결 방법을 찾을 수 있습니다. 클라우드 모니터링의 궁극적인 목표는 고성능의 신뢰할 수 있는 클라우드 서비스와 애플리케이션을 유지 관리하여 고객에게 더 나은 서비스를 제공하고 직원들이 효율성과 생산성을 유지할 수 있도록 하는 것입니다.
클라우드 모니터링을 사용하면 탁월한 고객 경험을 제공하고, 취약성을 식별하고, 실제 문제가 발생하기 전에 해결하고, 애플리케이션 오작동으로 인한 비즈니스 다운타임이나 운영 중단을 방지하고, 민감한 기밀 데이터를 보호하고, 보안 및 개인정보 보호 규정을 준수할 수 있습니다.
클라우드 모니터링은 물리적 인프라가 아니라 클라우드 기반 애플리케이션 및 서비스를 모니터링한다는 점에서 기존 인프라 모니터링 수준을 넘어섭니다. 애플리케이션 데이터, 성능, 가동 시간, 사용량 등에 대한 광범위한 지표를 수집하여 잠재적인 문제를 분석하고 식별할 수 있습니다. 클라우드 모니터링은 조직이 클라우드 리소스를 어떻게 사용하고 있는지에 대한 정보도 수집합니다. 해당 정보는 클라우드 예산 책정, 성능, 용량 등에 대해 더 정확한 정보를 바탕으로 결정을 내리는 데 도움이 될 수 있습니다.
모니터링이란?
서비스 운영 중 발생할 수 있는 이슈 및 오류에 대비하기 위해 관련 데이터를 수집하고 기록하는 것입니다.
메트릭(Metrics)은 시스템, 애플리케이션 또는 네트워크와 같은 IT 환경에서 측정 가능한 수치나 지표를 의미하며, 모니터링 시스템에서는 대상(Target)의 시스템 정보 또는 특정 프로세스의 메트릭을 가져옵니다.
메트릭을 가져온다고 했지만 이것은 “Pull-based monitoring system”에 적용되는 개념입니다.
모니터링 방식에는 2가지 방식이 존재합니다
- 가져오거나(pull-based monitoring system)
- 받거나(push-based monitoring system)
그렇다면, '무엇'을 가져올까요?
메트릭, 로그, 트레이스 ?
Trace
- Trace는 추적이란 의미를 가지고 있습니다. 합니다.
- 프로그램이나 데이터의 흐름을 따라 확인하기 위해 Trace를 모니터링
- 서비스간에서 발생된 요청이 어떻게 처리되었는지 기록된 로그가 대표적인 Trace입니다.
Metric
- Metric은 를 의미합니다. 하기 위해 Metric을 모니터링합니다.시스템의 가용성이나 퍼포먼스를 확인
- 서비스가 동작 중일 때 발생하는 여러 수치의 변화
- 현재 리소스(CPU, 메모리 등) 사용량이나 어떤 이벤트의 발생 수 등이 Metric이라고 할 수 있습니다.
컨테이너 인프라 환경에서는 크게 2가지 상태로 메트릭을 구분합니다.
시스템 메트릭(System Metric), HTTP 상태 코드 같은 서비스 상태를 나타내는 지표인 서비스 메트릭(Service Metric)입니다.파드 같은 오브젝트에서 측정되는 CPU와 메모리 사용량을 나타내는 메트릭(Metric)은 간단히 말해 현재 시스템의 상태를 알 수 있는측정값입니다.
Log
- Log는 을 말합니다. 애플리케이션 개발 시 사용된 라이브러리/프레임워크에서 발생되는 로그와 개발자가 의도해서 발생하도록 한 로그 등, 로그의 범위는 매우 넓습니다.
- 애플리케이션 실행 중에 발생되는 텍스트 기록
- 오류(Error)나 경고(Warning), 특수한 경우(Exception) 등의 이벤트 발생 시 이에 대한 정보를 알 수 있도록 기록한 것이 Log입니다.
무엇을 모니터링 해야할 까?
그렇다면 쿠버네티스 환경에서는 과연 무엇을 모니터링해야 할까요?
그것을 이해하기 위해 쿠버네티스 환경에서 발생할 수 있는 이슈 상황을 몇 가지 예로 들어 보겠습니다.
① 특정 노드가 다운되거나 Ready 상태가 아닌 경우 (컨트롤 플레인이 다중화되거나, 애플리케이션이 디플로이먼트와 같은 단위로 구성된 경우 보통은 큰 문제가 되지 않지만, 특정 상황에서는 문제가 될 수 있습니다.)
② 컨트롤 플레인의 주요 컴포넌트 상태가 비정상적인 경우
③ 노드의 가용한 리소스보다 리소스 요청량(Request)이 커서 파드가 배포되지 않는 경우
④ 노드 리소스가 부족하여 컨테이너의 크래시(혹은 eviction)가 발생한 경우
⑤ 특정 컨테이너가 OOMKilled나 그 밖의 문제로 인해 반복적으로 재시작하는 경우
⑥ PV로 할당하여 마운트된 파일시스템의 용량이 부족한 경우
다음 글에서는 인프라 모니터링에 주로 쓰이는 도구들을 소개하며 설계를 진행해보겠다.
'☁️2024,2025☁️ > Cloud' 카테고리의 다른 글
| CloudClub 7기 리크루팅 홍보 및 5~6기 회고 (0) | 2025.01.26 |
|---|---|
| [ Monitoring ] 인프라 모니터링 파이프라인 설계하기 #2 (0) | 2025.01.10 |
| [ AWS ] aws 서비스 살펴보기 #1 (1) | 2024.12.03 |
| KT cloud를 사용해왔던 이유 ( K-PaaS 공모전 참여 3등상 수상 후기 ) (5) | 2024.11.21 |
| [CloudClub] 클클 클라우드 플랫폼 제작 참여기 #1 (0) | 2024.11.11 |